About Me
 I am an enthusiast of mathematics, physics, and software
development who has been lucky enough to professionally pursue
all of these subjects.
I am an enthusiast of mathematics, physics, and software
development who has been lucky enough to professionally pursue
all of these subjects.
My current focus is in infrastructure development for scientific computing clusters. I recently joined the team at the Vanderbilt ACCRE facility. I was last employed at IBM Cloudant where I primarily worked on python applications that are deployed to manage several aspects of the cloud database service, such as metering, billing, account management, and platform integrations. I am also active in the Nashville Python community and a supporting member of the Python Software Foundation.
Before I decided to follow my interests in computing full time, I was a research physicist employed at Vanderbilt University pursuing research in heavy ion collisions in collaboration with the Compact Muon Solenoid (CMS) experiment, where we studied a novel state of nuclear matter momentarily produced in the collisions of large nuclei. Working with the CMS collaboration was a fantastic opportunity to combine my interests in computer science, mathematical modeling, and the physics of quarks and gluons while traveling the world as part of an international scientific effort.
My first professional job was teaching mathematics at University School of Nashville. One of my key insights from this experience is well expressed in this Feynman anecdote from David Goodstein’s book, Feynman’s Lost Lecture:
Feynman was a truly great teacher. He prided himself on being able to devise ways to explain even the most profound ideas to beginning students. Once, I said to him, “Dick, explain to me, so that I can understand it, why spin one-half particles obey Fermi-Dirac statistics.” Sizing up his audience perfectly, Feynman said, “I’ll prepare a freshman lecture on it.” But he came back a few days later to say, “I couldn’t do it. I couldn’t reduce it to the freshman level. That means we don’t really understand it.”
My personal philosophy towards software engineering is drawn from this sort of attitude. If I cannot reasonably document or explain something, this indicates that my own comprehension is lacking. For this reason, I consider the practice of writing complete documentation, crafting tutorials, and giving talks to be essential to ensuring the soundness of any software that I implement.
Here is a reasonably current resume.
Computing
Computing has always been a hobby of mine, starting in high school when I spent weekends configuring network services on desktop Linux systems while learning C and perl. As a professional physicist, I spent several years performing data analysis and stochastic simulations in C++ and python frameworks while also building monitoring tools for grid computing.
Aside from my work responsibilities, I am currently volunteering to help with documentation and test coverage for the python reference implementation (CPython). The largest contribution I have made so far is documenting PEP-525 and PEP-530 (asynchronous generators and comprehensions) in the Python Language Reference. My focus at the moment is on a project to rewrite the asyncio documentation. I hope to eventually increase my understanding of the C implementation of python to make larger contributions to the language runtime itself.
I decided to pursue software and computing full time based on the experience I had as a research scientist developing and maintaining data transfer and monitoring tools. These tools were used for the Vanderbilt Tier-2 CMS computing facility which is a part of the Vanderbilt ACCRE facility. One of the things I most enjoyed was writing a cluster monitoring system, originally as a set of bash scripts, and then as an informal python package. I called it AutoCMS and as of this writing it is still in operation monitoring the cluster. I used this package as a tool to transition to a professional developer, adding docstrings and automated unit tests.
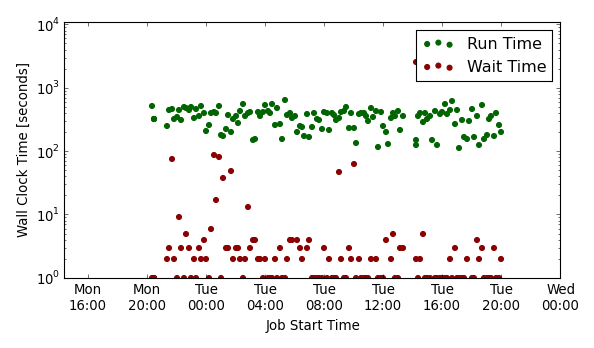 Snapshot of cluster performance using the AutoCMS monitoring system.
Snapshot of cluster performance using the AutoCMS monitoring system.
Over 1.5 Petabytes of collision data from the CMS experiment at the LHC are housed at the ACCRE facility using the L-Store logistical storage framework developed at Vanderbilt. Working closely with the operators and developers at the facility was a tremendous help in transitioning from physics to software as it gave me several years of experience working in a large scale computing facility.
Physics
From 2009 to 2015, I worked in collaboration with the Compact Muon Solenoid (CMS) experiment at the world’s most powerful particle accelerator, the Large Hadron Collider (LHC), to study the properties of nuclear matter at extreme temperatures of over a trillion degrees Kelvin. The CMS experiment is a $500 million international detector system with excellent capabilities to precisely determine the momentum of charged particles created in collisions between protons or heavy nuclei.
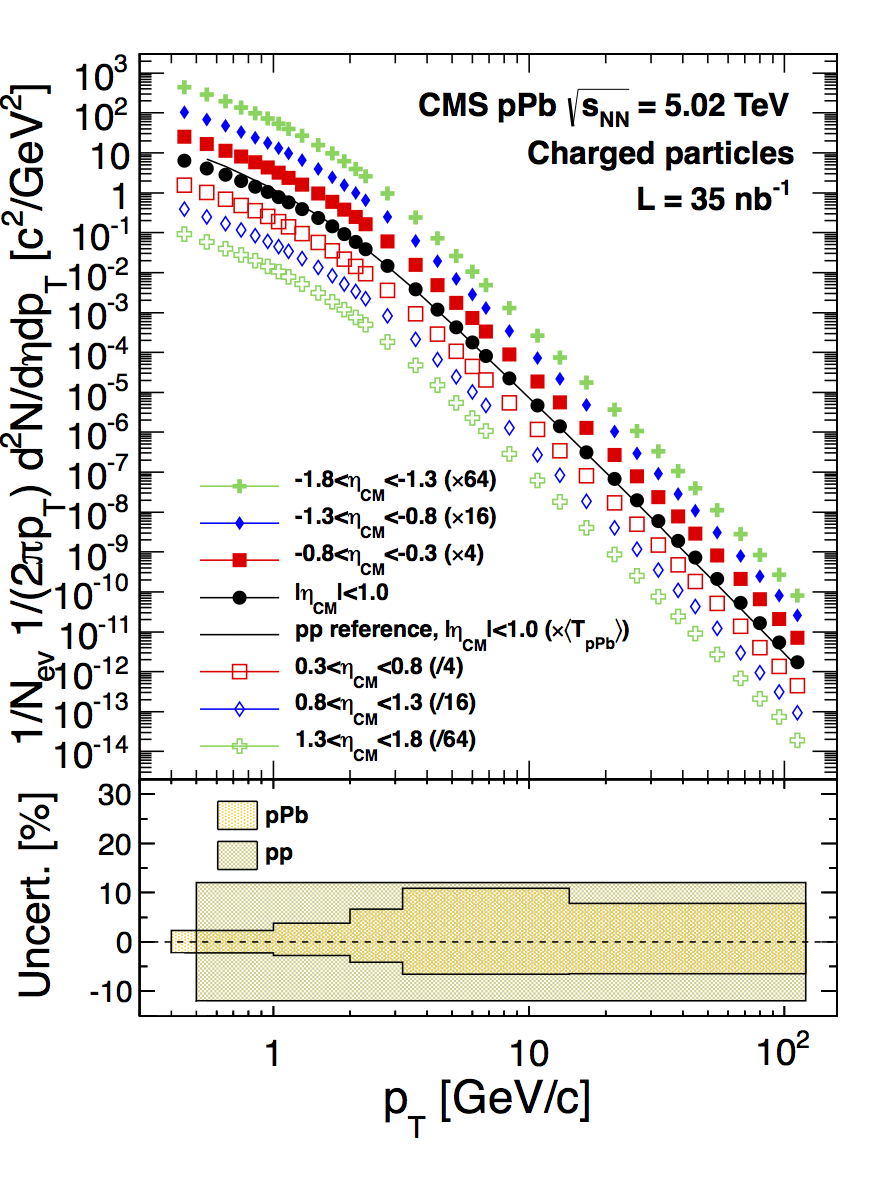 CMS Collaboration, Eur. Phys. J. C 75 (2015) 237
doi:10.1140/epjc/s10052-015-3435-4
CMS Collaboration, Eur. Phys. J. C 75 (2015) 237
doi:10.1140/epjc/s10052-015-3435-4
By colliding two heavy nuclei at close to the speed of light, a high temperature bulk system can be created for a very short span of time, in which the protons and neutrons that comprise the nuclei are predicted to undergo a phase transition into a new state of nuclear matter often called a Quark-Gluon Plasma.
My thesis work focused on the measurement of charged particles produced in collisions between a single proton and a heavy nucleus, which helps to enhance the understanding of the various effects that modify charged particle production in nucleus-nucleus collisions relative to proton-proton collisions.